Chi Square Goodness Of Fit

Oké, even een verhaal om erin te komen. Stel je voor: je staat op de kermis, recht voor het rad van fortuin. Die dingen met allemaal vakjes, je kent ze wel. Er wordt beweerd dat elk vakje evenveel kans heeft om te winnen. Maar jij bent sceptisch. Je ziet een paar vakjes er net iets groter uitzien, of misschien zijn ze iets anders gekleurd. Voel je die twijfel? Dat is precies waar de Chi-kwadraat goodness-of-fit test om de hoek komt kijken!
Eigenlijk is de Chi-kwadraat goodness-of-fit test een tool om te bepalen of je waargenomen data overeenkomt met de verwachte data. In het kermisvoorbeeld: is de daadwerkelijke frequentie waarmee elk vakje wint gelijk aan wat je zou verwachten als elk vakje echt evenveel kans had?
Wat is de Chi-kwadraat Goodness-of-Fit Test?
De officiële definitie is misschien een beetje droog, maar laat je niet afschrikken. Het is simpeler dan het klinkt. In essentie test de Chi-kwadraat goodness-of-fit of een waargenomen frequentieverdeling significant verschilt van een theoretische (verwachte) frequentieverdeling. Dus, nogmaals, klopt wat je ziet met wat je zou verwachten?
Must Read
Denk erover na: als je een eerlijke dobbelsteen 60 keer gooit, dan verwacht je dat je ongeveer 10 keer een 1 gooit, 10 keer een 2, enzovoort. Maar wat als je 20 keer een 1 gooit en maar 5 keer een 6? Begint er dan iets te knagen? De Chi-kwadraat test helpt je te bepalen of die afwijking significant genoeg is om de hypothese te verwerpen dat de dobbelsteen eerlijk is. (Tenzij je natuurlijk bewust vals speelt. Maar dat terzijde.)
Wanneer gebruik je deze test?
De Chi-kwadraat goodness-of-fit test is perfect voor situaties waarin:
- Je te maken hebt met categorische data (zoals kleuren, soorten, etc.).
- Je een hypothese hebt over hoe die categorieën verdeeld zouden moeten zijn.
- Je wilt testen of je waargenomen data significant afwijken van die hypothese.
Bijvoorbeeld:
- Genetica: Verhoudingen van fenotypes in een kruising. (Mendel, iemand?)
- Marketing: Is er een voorkeur voor bepaalde kleuren in een productlijn?
- Verkeer: Is de verdeling van auto's per kleur op de snelweg gelijk aan de verdeling van verkochte auto's per kleur? (Denk erover na... zou dat zo zijn?)
Hoe werkt het? (Zonder te veel wiskunde-paniek!)
Oké, we gaan niet verdwalen in formules, maar een beetje begrip is wel handig. Het kernidee is dat je een zogenaamde Chi-kwadraat statistic berekent. Deze statistic meet het verschil tussen je waargenomen en verwachte waarden.

De formule (je hoeft hem niet uit je hoofd te leren, beloofd!):
Χ2 = Σ [(O - E)2 / E]
Waarbij:
- Χ2 is de Chi-kwadraat statistic.
- Σ betekent "de som van".
- O is de waargenomen waarde (observed).
- E is de verwachte waarde (expected).
In woorden: voor elke categorie neem je het verschil tussen de waargenomen en verwachte waarde, kwadrateert dit, deelt het door de verwachte waarde, en telt al die resultaten bij elkaar op. That's it!
Hoe groter de Chi-kwadraat statistic, hoe groter het verschil tussen je waargenomen en verwachte data, en hoe groter de kans dat je hypothese niet klopt. (Logisch, toch?)

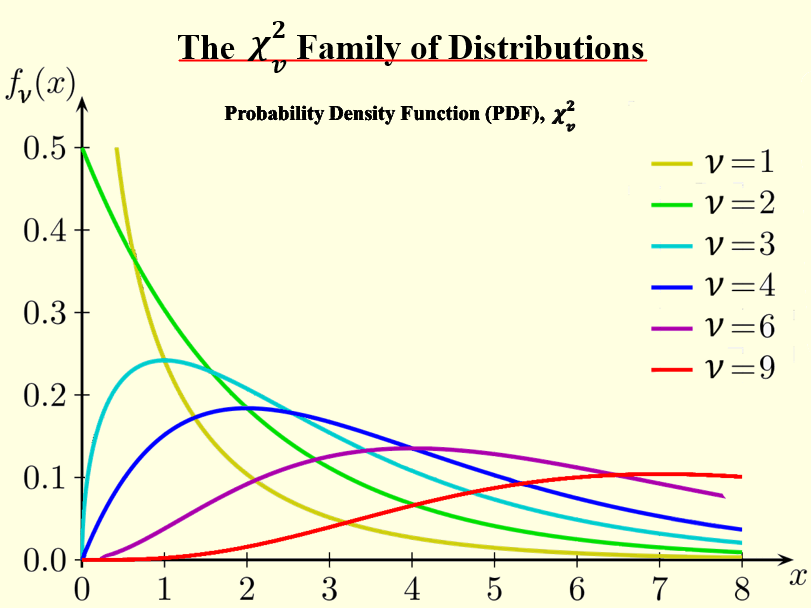
Degrees of Freedom (Vrijheidsgraden)
Nog een belangrijk concept: degrees of freedom (df) of vrijheidsgraden. Dit is het aantal categorieën min 1. Waarom? Omdat als je het totaal aantal observaties weet en alle waarden behalve één, je de laatste waarde kunt berekenen. Die laatste waarde is dus niet "vrij" om te variëren. In de dobbelsteen voorbeeld, met 6 categorieën (1 t/m 6), zou je df = 6 - 1 = 5 hebben.
P-waarde en Significantie
De Chi-kwadraat statistic en de degrees of freedom worden gebruikt om een p-waarde te bepalen. De p-waarde is de kans dat je de waargenomen resultaten (of resultaten die nog extremer zijn) zou krijgen, als de nulhypothese (de hypothese die je wilt testen) waar zou zijn.
Meestal wordt een significantieniveau van 0.05 gebruikt. Dit betekent dat als de p-waarde kleiner is dan 0.05, je de nulhypothese verwerpt. Met andere woorden: je waargenomen data wijken significant af van wat je zou verwachten.
Stel, in het dobbelsteen voorbeeld, dat je een Chi-kwadraat statistic berekent en een p-waarde van 0.02 krijgt. Omdat 0.02 < 0.05, verwerp je de hypothese dat de dobbelsteen eerlijk is. Je data suggereren dus dat er iets mis is met die dobbelsteen. (Misschien is hij verzwaard aan één kant? Intrigerend!)

Stappenplan voor de Chi-kwadraat Goodness-of-Fit Test
Even samenvatten in een handig stappenplan:
- Formuleer je hypothese: Wat verwacht je te zien? (Bijvoorbeeld: "Elke kant van de dobbelsteen heeft een gelijke kans om boven te komen.")
- Verzamel je data: Voer je experiment uit en noteer de waargenomen frequenties voor elke categorie.
- Bereken de verwachte frequenties: Gebaseerd op je hypothese, hoe vaak zou je elke categorie verwachten?
- Bereken de Chi-kwadraat statistic: Gebruik de formule Χ2 = Σ [(O - E)2 / E].
- Bepaal de degrees of freedom: df = aantal categorieën - 1.
- Zoek de p-waarde op: Gebruik een Chi-kwadraat tabel of een statistische software om de p-waarde te bepalen.
- Neem een beslissing: Als de p-waarde < significantieniveau (meestal 0.05), verwerp je de nulhypothese.
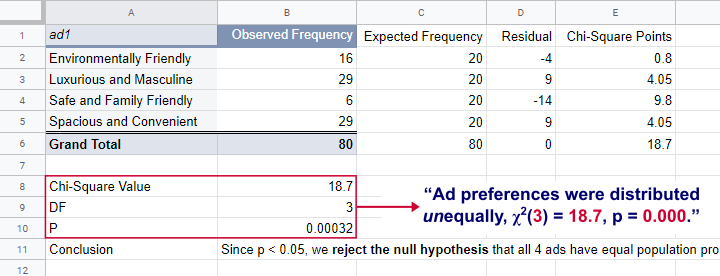
Een simpel voorbeeld
Laten we een eenvoudig voorbeeld bekijken. Stel je voor dat je een zak M&M's koopt en je wilt testen of de kleuren in de zak overeenkomen met de percentages die Mars (de fabrikant) claimt.
Mars beweert de volgende verdeling:
- Bruin: 30%
- Geel: 20%
- Rood: 20%
- Blauw: 10%
- Oranje: 10%
- Groen: 10%
Je telt de M&M's in je zak en vindt de volgende aantallen:
- Bruin: 50
- Geel: 30
- Rood: 25
- Blauw: 10
- Oranje: 15
- Groen: 10
Je hebt in totaal 140 M&M's. Nu kun je de verwachte aantallen berekenen:

- Bruin: 0.30 * 140 = 42
- Geel: 0.20 * 140 = 28
- Rood: 0.20 * 140 = 28
- Blauw: 0.10 * 140 = 14
- Oranje: 0.10 * 140 = 14
- Groen: 0.10 * 140 = 14
Nu kun je de Chi-kwadraat statistic berekenen (ik doe dit niet helemaal hier, want anders wordt het te lang, maar het principe is duidelijk):
Na de berekening stel dat je een Chi-kwadraat statistic van 3.45 krijgt. Je degrees of freedom zijn 6 - 1 = 5. Met behulp van een Chi-kwadraat tabel (of online calculator) vind je dat de p-waarde ongeveer 0.63 is. Omdat 0.63 > 0.05, verwerp je de nulhypothese niet. Je data geven geen significant bewijs dat de kleuren in jouw zak M&M's afwijken van de geclaimde verdeling.
Conclusie: Misschien moet je gewoon meer M&M's eten om een grotere steekproef te krijgen! (En wie ben ik om dat af te raden?)
Belangrijke Overwegingen
Een paar dingen om in gedachten te houden:
- Steekproefgrootte: De Chi-kwadraat test werkt het beste met grote steekproeven. Een algemene regel is dat de verwachte waarde voor elke categorie minstens 5 moet zijn. Zo niet, dan kun je categorieën samenvoegen.
- Onafhankelijkheid: De observaties moeten onafhankelijk van elkaar zijn. Met andere woorden, de waarde van één observatie mag geen invloed hebben op de waarde van een andere observatie.
- Alleen voor categorische data: De Chi-kwadraat goodness-of-fit test is alleen geschikt voor categorische data. Voor continue data zijn er andere tests.
Conclusie
De Chi-kwadraat goodness-of-fit test is een krachtige tool om te bepalen of je waargenomen data overeenkomt met een verwachte verdeling. Of je nu de eerlijkheid van een dobbelsteen wilt testen, de verdeling van kleuren in een zak M&M's wilt analyseren, of de genetische verhoudingen in een experiment wilt onderzoeken, deze test kan je helpen om statistisch onderbouwde conclusies te trekken. Dus, de volgende keer dat je iets ziet dat er verdacht uitziet, weet je wat je moet doen: Chi-kwadraat erop los!










/latex_ac74fec08532861eb5f8b87226ebf396-5c59a6fcc9e77c00016b4195.jpg)


