Assumptions Of Multiple Regression Analysis

Oké, stel je voor: je bakt een taart. Een héél lekkere taart. Je stopt er eieren in, bloem, suiker, boter… en een snufje liefde, natuurlijk! Maar wat als je opeens besluit om er ook een handje zout aan toe te voegen, in plaats van suiker? Oeps, dat wordt een heel andere taart! Dat is een beetje wat er gebeurt als je Multiple Regressie gebruikt zonder te kijken naar de 'ingrediënten', de assumpties.
Multiple Regressie, klinkt ingewikkeld hè? Maar eigenlijk is het gewoon een fancy manier om te kijken hoe verschillende dingen (zoals eieren, bloem, suiker) invloed hebben op iets anders (de smaak van je taart). We willen dus voorspellen, op basis van die 'ingrediënten'. Maar net als bij bakken, moet je wel even checken of alles wel klopt!
Waarom Zou Je Hier Om Geven?
Nou, ten eerste: niemand wil een zoute taart. In de 'echte' wereld betekent een verkeerde analyse dat je misschien de verkeerde beslissingen neemt. Stel je voor: je bent een marketeer en wilt weten welke factoren (advertenties op tv, online, in de krant) de meeste invloed hebben op je verkoopcijfers. Als je de assumpties van regressie negeert, kom je misschien tot de conclusie dat tv-reclame super belangrijk is, terwijl het eigenlijk de online advertenties zijn die het meeste effect hebben! Zonde van je geld en moeite, toch?
Must Read
Ten tweede, en misschien nog wel belangrijker: het geeft je een dieper inzicht. Door te controleren of de assumpties kloppen, leer je meer over de data waarmee je werkt. Je ontdekt patronen, rare uitschieters en misschien zelfs verrassende verbanden die je anders over het hoofd zou zien. Het is alsof je de ingrediënten van je taart leert kennen op een dieper niveau!
De Belangrijkste Assumpties (En Waarom Ze Cruciaal Zijn)
Laten we eens kijken naar die 'ingrediënten' van de regressie, de assumpties. Er zijn er een paar belangrijke, die we één voor één gaan bekijken. Geen paniek, het is minder eng dan het klinkt!
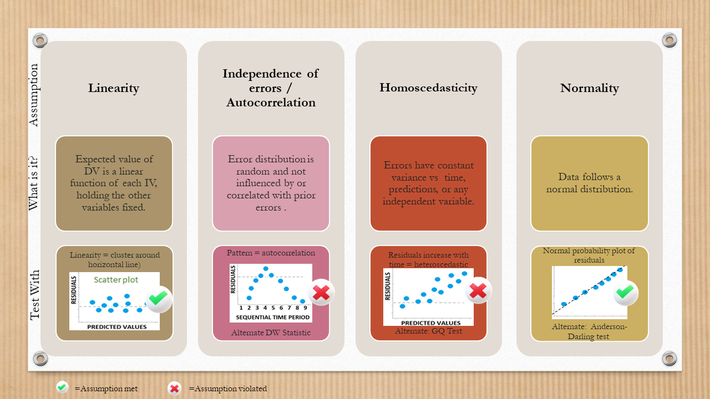
1. Lineariteit: Een Rechte Lijn, Graag!
Dit betekent dat de relatie tussen de voorspellende variabelen (eieren, bloem, suiker) en de variabele die je wilt voorspellen (smaak van de taart) lineair moet zijn. Dus, als je meer suiker toevoegt, moet de taart (ongeveer) evenredig zoeter worden.

Waarom is dit belangrijk? Stel dat meer suiker toevoegen de taart eerst zoeter maakt, maar op een gegeven moment te zoet, waardoor de smaak weer minder lekker wordt. Dan is de relatie niet lineair! Regressie gaat er vanuit dat er een rechte lijn is, en als die er niet is, kloppen de resultaten niet. Je kunt dit checken door spreidingsdiagrammen te maken. Zie je een kromme in de puntenwolk? Dan is er waarschijnlijk geen lineaire relatie.
2. Onafhankelijkheid van de Fouten: Geen Gekonkel Achter De Schermen
Dit klinkt heel technisch, maar het betekent eigenlijk dat de 'fouten' die de regressie maakt (dus het verschil tussen de voorspelde en de echte waarde) niet met elkaar samenhangen. Het is alsof de mislukkingen van de ene taart niks te maken mogen hebben met de mislukkingen van de andere. Elk baksel staat op zichzelf.
Waarom is dit belangrijk? Stel je voor dat je verschillende taarten bakt op dezelfde dag, met dezelfde oven. Als de oven niet goed werkt, zullen alle taarten waarschijnlijk mislukken. De 'fouten' zijn dus afhankelijk van elkaar! In regressie betekent dit dat de standaardfouten van je schattingen (hoe precies je voorspelling is) verkeerd berekend worden. En dan trek je dus de verkeerde conclusies.
Je kunt dit checken met de Durbin-Watson test. Een waarde rond de 2 is goed. Veel lager of hoger kan wijzen op problemen.

3. Homoscedasticiteit: Eerlijke Spreiding, Voor Iedereen!
Probeer dit maar eens uit te spreken, homoscedasticiteit! Wat het betekent is dat de spreiding van de fouten constant moet zijn over alle waarden van de voorspellende variabelen. Met andere woorden, de 'onnauwkeurigheid' van je voorspelling moet ongeveer hetzelfde zijn, ongeacht hoeveel eieren, bloem of suiker je gebruikt.
Waarom is dit belangrijk? Stel dat je voorspelling heel precies is als je weinig suiker gebruikt, maar heel onnauwkeurig wordt als je veel suiker gebruikt. Dan is er geen homoscedasticiteit! Dit kan leiden tot verkeerde conclusies over de significantie van je variabelen. Je denkt misschien dat suiker een heel belangrijke factor is, terwijl de onnauwkeurigheid van je metingen roet in het eten gooit.
Je kunt dit checken door naar de residuenplot te kijken (een grafiek van de fouten). Zie je een trechtervorm? Dan is er waarschijnlijk geen homoscedasticiteit.

4. Normaliteit van de Fouten: Een Belletje Voor Normaal Gedrag
Nog zo'n lekker woord! Dit betekent dat de fouten normaal verdeeld moeten zijn. Alsof de fouten netjes in een belletje passen, met de meeste fouten rond het gemiddelde.
Waarom is dit belangrijk? Veel statistische tests (zoals de t-test en de F-test) zijn gebaseerd op de aanname van normaliteit. Als de fouten niet normaal verdeeld zijn, zijn deze tests minder betrouwbaar. Vooral bij kleine steekproeven kan dit een groot probleem zijn.
Je kunt dit checken met een histogram van de residuen, of met een Q-Q plot. Zien ze er ongeveer uit als een klokvorm, of liggen de punten op de Q-Q plot netjes op een rechte lijn? Dan is de kans groot dat de fouten normaal verdeeld zijn.
5. Geen Multicollineariteit: Geen Ruzie Tussen De Ingrediënten
Dit betekent dat de voorspellende variabelen niet te sterk met elkaar samen mogen hangen. Stel je voor dat je suiker en honing gebruikt in je taart. Ze hebben allebei hetzelfde effect (zoeter maken), en het is moeilijk om te zeggen welke van de twee nou echt belangrijk is. Ze 'overlappen' elkaar te veel. Het is als twee koks die tegelijkertijd hetzelfde proberen te doen in een kleine keuken – dat geeft ruzie!

Waarom is dit belangrijk? Multicollineariteit maakt het moeilijk om de afzonderlijke effecten van de variabelen te bepalen. De coëfficiënten (hoeveel invloed elke variabele heeft) worden instabiel en moeilijk te interpreteren. Het is alsof je niet meer weet of het de suiker of de honing is die je taart zoet maakt!
Je kunt dit checken door de correlatie tussen de voorspellende variabelen te bekijken, of door de Variance Inflation Factor (VIF) te berekenen. Een VIF hoger dan 5 of 10 kan wijzen op multicollineariteit.
Wat Nu? Problemen Opgelost!
Oké, je hebt de assumpties gecheckt en... oeps! Er is er eentje niet in orde. Geen paniek! Er zijn altijd oplossingen:
- Lineariteit: Probeer de variabelen te transformeren (bijvoorbeeld logaritmisch of kwadratisch). Of, gebruik een ander model, zoals een niet-lineair model.
- Onafhankelijkheid van de fouten: Dit is vaak lastiger op te lossen. Soms helpt het om extra variabelen toe te voegen aan het model, of om te kijken of er sprake is van een tijdsafhankelijke structuur in de data.
- Homoscedasticiteit: Probeer de afhankelijke variabele te transformeren, of gebruik gewogen kleinste kwadraten regressie.
- Normaliteit van de fouten: Als de afwijkingen niet te groot zijn, is het vaak geen probleem. Bij grote afwijkingen, overweeg niet-parametrische methoden.
- Multicollineariteit: Verwijder één van de sterk gecorreleerde variabelen, of combineer ze tot één variabele. Of, gebruik Principal Component Regression.
Conclusie: Bak Met Kennis!
Multiple Regressie is een krachtige tool, maar net als elke tool, moet je hem met de juiste kennis gebruiken. Door de assumpties te begrijpen en te controleren, zorg je ervoor dat je betrouwbare resultaten krijgt en de juiste beslissingen neemt. En net als bij het bakken van een taart, is het belangrijk om te weten wat je doet, zodat je uiteindelijk kunt genieten van een heerlijk resultaat! Dus, wees niet bang om de 'ingrediënten' van je analyse te controleren – het loont de moeite!