Assumptions Of Linear Regression Analysis
Lieve studenten, ik snap het helemaal. Lineaire regressie en al die aannames... het kan voelen alsof je door een doolhof wandelt. Maar geen paniek! Samen maken we dit helder en behapbaar. Geen ingewikkelde formules in het begin, gewoon stap voor stap de basics begrijpen. Dus, adem in, adem uit, en laten we beginnen.
Wat zijn die aannames nou eigenlijk?
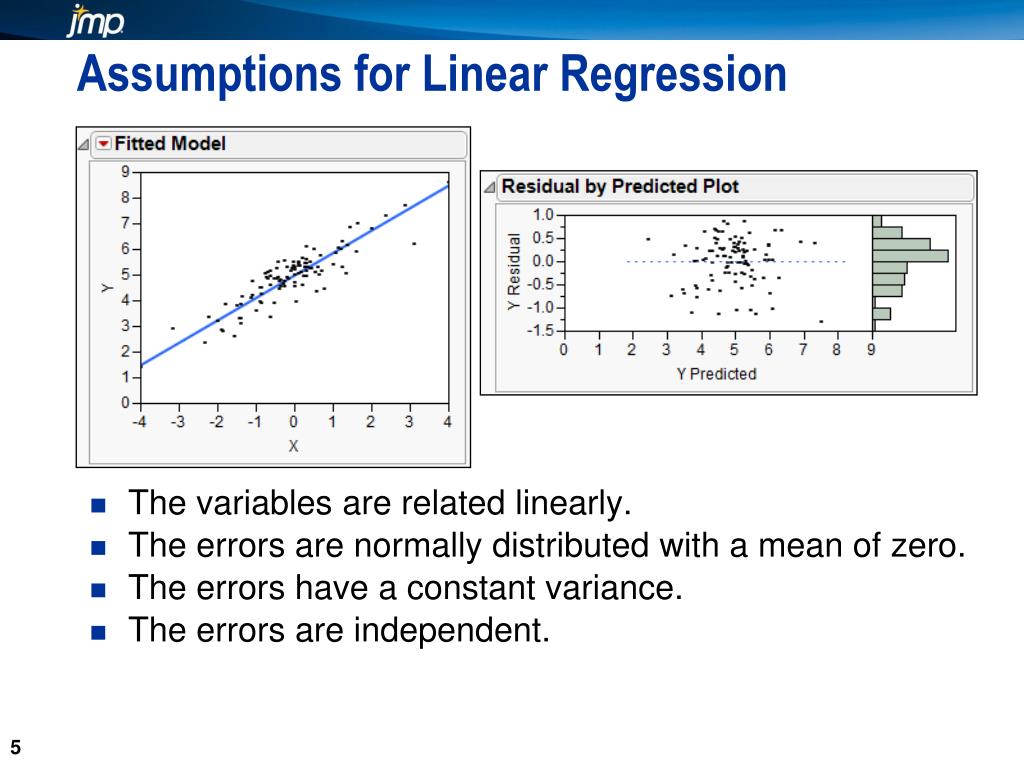
Lineaire regressie is een krachtige tool, maar hij werkt het best als aan bepaalde voorwaarden is voldaan. Deze voorwaarden noemen we aannames. Zie het als de ideale omstandigheden voor een perfecte taart. Als je cruciale ingrediënten vergeet, is het resultaat misschien niet wat je ervan had gehoopt. Zo is het ook met lineaire regressie. Laten we kijken naar de belangrijkste aannames:
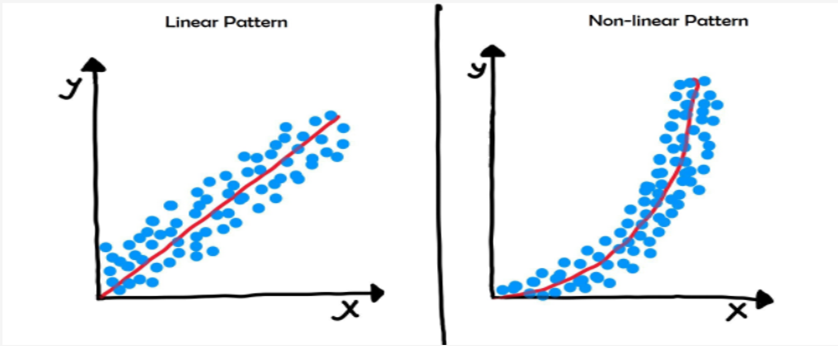
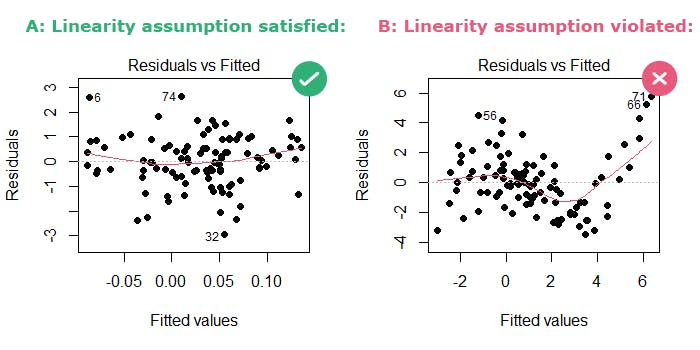
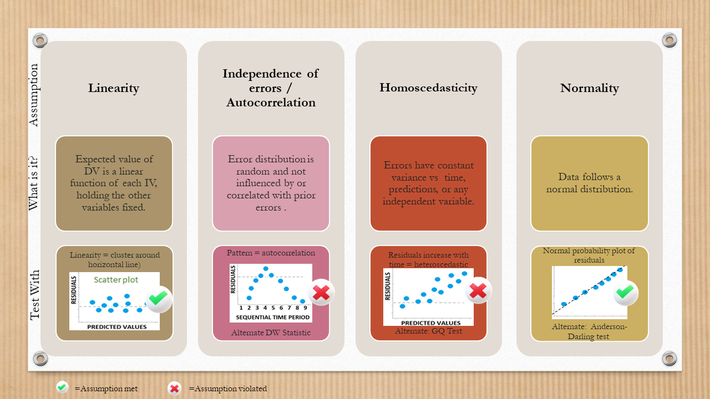
1. Lineariteit
Deze aanname zegt eigenlijk dat er een lineaire relatie moet zijn tussen de onafhankelijke variabele(n) en de afhankelijke variabele. Met andere woorden, als je een grafiek zou maken van de relatie, zou je idealiter een rechte lijn zien.
Must Read
Praktisch voorbeeld: Stel je voor, je onderzoekt het verband tussen het aantal uren dat iemand studeert en het cijfer dat ze halen voor een tentamen. Als meer studeren consequent leidt tot hogere cijfers, en die toename min of meer constant is, dan is er waarschijnlijk sprake van lineariteit.
2. Onafhankelijkheid van de Residuen
De residuen zijn de verschillen tussen de voorspelde waarden en de daadwerkelijke waarden. Deze aanname stelt dat deze residuen onafhankelijk van elkaar moeten zijn. Dat betekent dat de fout die je maakt bij het voorspellen van de ene waarde, geen invloed heeft op de fout die je maakt bij het voorspellen van een andere waarde.

Praktisch voorbeeld: Denk aan een tijdreeksanalyse van de verkoop van ijsjes. Als de verkoop op de ene dag afhankelijk is van de verkoop op de vorige dag (bijvoorbeeld door het weer), dan schend je deze aanname.
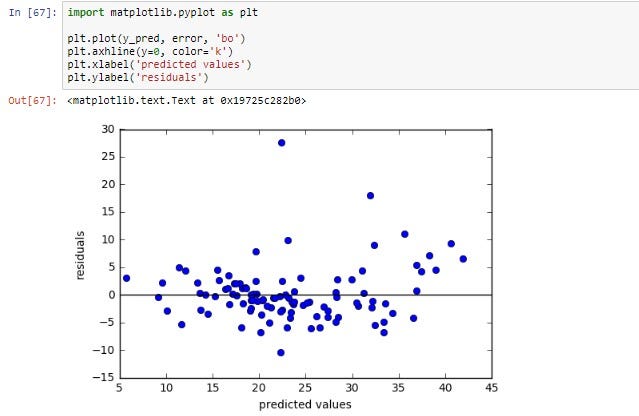
3. Homoscedasticiteit (Constante Variantie)
Dit is een moeilijke term, maar het betekent simpelweg dat de variantie (spreiding) van de residuen constant moet zijn over alle niveaus van de onafhankelijke variabele(n). In een grafiek zou je een wolk van punten zien die min of meer dezelfde breedte heeft over de hele lengte.
Praktisch voorbeeld: Stel, je onderzoekt het verband tussen inkomen en uitgaven. Als mensen met een laag inkomen een kleinere spreiding in hun uitgaven hebben dan mensen met een hoog inkomen (omdat ze minder besteedbaar inkomen hebben), dan is er sprake van heteroscedasticiteit (het tegenovergestelde van homoscedasticiteit).
4. Normaliteit van de Residuen
De aanname van normaliteit stelt dat de residuen normaal verdeeld moeten zijn. Dit betekent dat als je een histogram zou maken van de residuen, het zou lijken op een belvormige curve (een normale verdeling).
Praktisch voorbeeld: In veel natuurlijke processen komen normale verdelingen voor. Denk aan de lengte van mensen of de fouten die gemaakt worden bij het meten van iets. Als de residuen significant afwijken van een normale verdeling, kan dit een teken zijn van problemen met je model.

5. Geen Multicollineariteit (bij meerdere onafhankelijke variabelen)
Als je meerdere onafhankelijke variabelen hebt, dan wil je dat deze variabelen niet te sterk met elkaar samenhangen (multicollineariteit). Als ze dat wel doen, kan het moeilijk zijn om de individuele effecten van elke variabele te bepalen.
Praktisch voorbeeld: Stel je voor dat je het verband onderzoekt tussen de grootte van een huis (in vierkante meters) en de prijs, en je neemt ook het aantal slaapkamers mee als onafhankelijke variabele. Omdat er vaak een sterke correlatie is tussen het aantal vierkante meters en het aantal slaapkamers, kan multicollineariteit een probleem vormen.

Wat als de aannames niet kloppen?
Het is niet altijd mogelijk om aan alle aannames perfect te voldoen. Maar als de aannames sterk geschonden worden, kunnen de resultaten van je analyse onbetrouwbaar zijn. Gelukkig zijn er manieren om deze problemen aan te pakken, bijvoorbeeld door:
- De data te transformeren (bijvoorbeeld log transformatie)
- Andere variabelen toe te voegen aan het model
- Een andere analysemethode te gebruiken
Het is belangrijk om je bewust te zijn van deze aannames en om te controleren of ze redelijk zijn. Door dit te doen, kun je ervoor zorgen dat je de juiste conclusies trekt uit je analyse.
En onthoud, het is oké om fouten te maken! Statistiek is een leerproces, en met oefening en geduld zul je deze aannames steeds beter begrijpen. Je kunt dit!