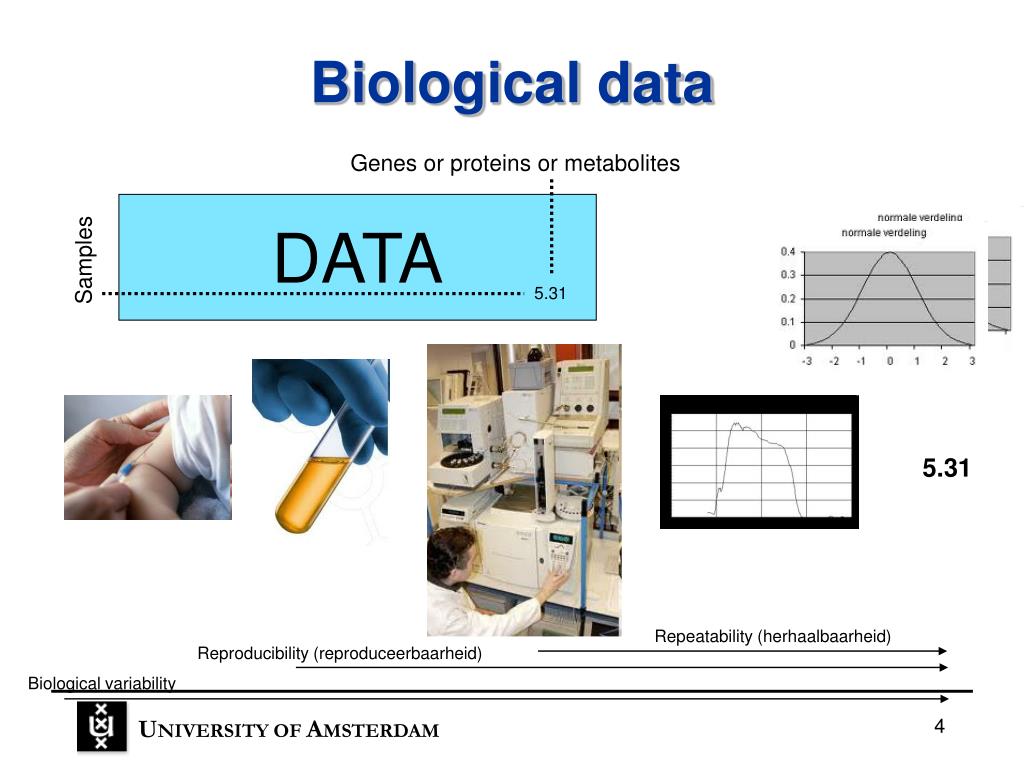
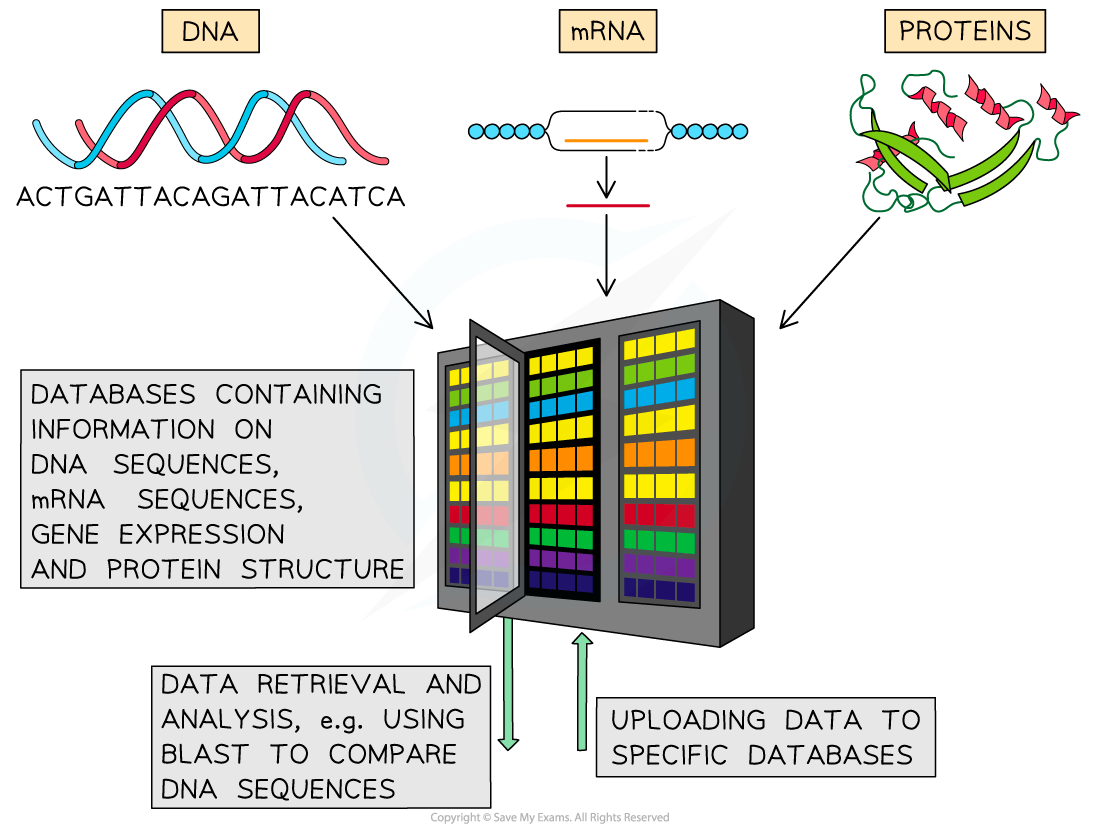
Analysis Of Biological Data Whitlock

In de wereld van de moderne biologie genereert onderzoek steeds grotere en complexere datasets. De analyse van deze data is cruciaal voor het trekken van betrouwbare conclusies en het bevorderen van ons begrip van levende systemen. Een sleutelwerk in dit vakgebied is "Analysis of Biological Data" door Michael Whitlock en Dolph Schluter. Dit artikel biedt een diepgaande blik op de kernprincipes en argumenten die in dit boek worden uiteengezet, en illustreert hoe deze principes in de praktijk worden toegepast.
Kernprincipes van Biologische Data Analyse volgens Whitlock & Schluter
Het boek "Analysis of Biological Data" benadrukt een aantal fundamentele concepten die essentieel zijn voor een correcte en robuuste analyse van biologische data. Het legt de nadruk op het belang van statistische basisprincipes en het correct toepassen van verschillende statistische methoden.
Statistische Basisprincipes: De Fundering
Een cruciaal aspect is het begrijpen van de onderliggende probabilistische principes. Dit omvat het concept van kansverdelingen, zoals de normale verdeling en de binomiale verdeling, en hoe deze verdelingen gebruikt kunnen worden om de waarschijnlijkheid van bepaalde uitkomsten te modelleren. Het boek legt ook de nadruk op het belang van het begrijpen van de verschillen tussen beschrijvende en inferentiële statistiek. Beschrijvende statistiek omvat het samenvatten en presenteren van data (bijvoorbeeld met gemiddelden en standaarddeviaties), terwijl inferentiële statistiek het trekken van conclusies over een populatie op basis van een steekproef omvat.
Must Read
Whitlock en Schluter besteden veel aandacht aan het correct interpreteren van p-waarden. De p-waarde is de kans om een resultaat te observeren dat minstens zo extreem is als het geobserveerde resultaat, gegeven dat de nulhypothese waar is. Een kleine p-waarde (bijvoorbeeld kleiner dan 0.05) wordt vaak gebruikt als bewijs tegen de nulhypothese, maar het is belangrijk om te onthouden dat een p-waarde niet de kans is dat de nulhypothese waar is. Het misinterpreteren van p-waarden is een veelvoorkomende valkuil in de wetenschap.
Een ander belangrijk concept is het onderscheid tussen statistische significantie en biologische relevantie. Een statistisch significant resultaat betekent dat het onwaarschijnlijk is dat het resultaat door toeval is ontstaan, maar het betekent niet noodzakelijkerwijs dat het resultaat biologisch significant is. Een klein effect kan statistisch significant zijn als de steekproefgrootte groot genoeg is, maar het effect kan in de praktijk irrelevant zijn.
Hypothese Toetsing en Experimenteel Ontwerp
Het formuleren van duidelijke en testbare hypothesen is essentieel voor goed onderzoek. Het boek benadrukt het belang van het ontwerpen van experimenten die de hypothesen adequaat kunnen testen. Dit omvat het kiezen van een geschikte controlegroep, het randomiseren van behandelingen, en het controleren van confounding variabelen (variabelen die zowel de onafhankelijke als de afhankelijke variabele beïnvloeden). Het boek legt ook de nadruk op het belang van replicatie: het herhalen van experimenten om de betrouwbaarheid van de resultaten te vergroten.
Whitlock en Schluter behandelen uitgebreid verschillende hypothese toetsen, zoals t-toetsen, ANOVA (Analysis of Variance), en chi-kwadraat toetsen. Ze leggen uit wanneer elke toets geschikt is en hoe de resultaten correct geïnterpreteerd moeten worden. Ze benadrukken ook het belang van het controleren op de assumpties van de toetsen (bijvoorbeeld normaliteit en homogeniteit van variantie). Als de assumpties niet voldaan zijn, zijn er alternatieve, non-parametrische toetsen die gebruikt kunnen worden.

Regressie en Correlatie
Regressieanalyse wordt gebruikt om de relatie tussen een afhankelijke variabele en een of meer onafhankelijke variabelen te modelleren. Het boek behandelt zowel lineaire als niet-lineaire regressie, en legt uit hoe de parameters van het regressiemodel geïnterpreteerd kunnen worden. Het benadrukt ook het belang van het controleren op residuën (de verschillen tussen de geobserveerde waarden en de voorspelde waarden) om te bepalen of het regressiemodel adequaat is. Correlatie meet de sterkte en richting van de lineaire relatie tussen twee variabelen. Het boek benadrukt dat correlatie geen causaliteit impliceert. Twee variabelen kunnen gecorreleerd zijn zonder dat de ene variabele de andere veroorzaakt.
Analyse van Categorische Data
Biologische data is niet altijd numeriek. Soms is het categorisch, zoals de aan- of afwezigheid van een bepaalde eigenschap, of de kleur van een organisme. Het boek behandelt verschillende methoden voor het analyseren van categorische data, zoals de chi-kwadraat toets en logistische regressie. De chi-kwadraat toets wordt gebruikt om de onafhankelijkheid van twee categorische variabelen te testen. Logistische regressie wordt gebruikt om de relatie tussen een categorische afhankelijke variabele en een of meer onafhankelijke variabelen te modelleren.
Voorbeelden en Data Illustraties
Het boek "Analysis of Biological Data" bevat talrijke voorbeelden uit verschillende biologische disciplines, waaronder ecologie, evolutie, genetica, en fysiologie. Deze voorbeelden illustreren hoe de statistische principes in de praktijk toegepast kunnen worden. Laten we enkele illustraties bekijken.

- Ecologie: Een studie onderzoekt de relatie tussen de dichtheid van een bepaalde plantensoort en de aanwezigheid van een bepaalde insectensoort. De data worden geanalyseerd met behulp van regressieanalyse om te bepalen of er een significante relatie is tussen de twee variabelen.
- Evolutie: Een studie onderzoekt de verandering in allele frequenties in een populatie over tijd. De data worden geanalyseerd met behulp van een chi-kwadraat toets om te bepalen of de veranderingen in allele frequenties significant afwijken van wat verwacht zou worden onder de nulhypothese van geen evolutie.
- Genetica: Een studie onderzoekt de associatie tussen een bepaald gen en een bepaalde ziekte. De data worden geanalyseerd met behulp van logistische regressie om te bepalen of er een significante associatie is tussen het gen en de ziekte.
Een specifiek voorbeeld is de studie van Darwin's vinken op de Galapagoseilanden. Onderzoekers hebben de snavelgrootte van verschillende vinkensoorten gemeten en de data geanalyseerd met behulp van ANOVA om te bepalen of er significante verschillen zijn in snavelgrootte tussen de soorten. De resultaten laten zien dat de snavelgrootte varieert tussen de soorten, wat een aanpassing is aan verschillende voedselbronnen. Dit is een krachtig voorbeeld van natuurlijke selectie.
Een ander voorbeeld is het onderzoek naar de effecten van klimaatverandering op de distributie van soorten. Onderzoekers gebruiken regressieanalyse om de relatie tussen de temperatuur en de aanwezigheid van een bepaalde soort te modelleren. De resultaten kunnen gebruikt worden om te voorspellen hoe de distributie van de soort zal veranderen als de temperatuur stijgt. Dit is cruciaal voor het ontwikkelen van behoudsstrategieën.

Conclusie en Aanbevelingen
"Analysis of Biological Data" van Whitlock en Schluter is een onmisbare bron voor iedereen die biologische data analyseert. Het boek biedt een grondige en toegankelijke introductie tot de statistische principes die essentieel zijn voor goed onderzoek. Het legt de nadruk op het belang van het begrijpen van de onderliggende assumpties van statistische toetsen, het correct interpreteren van p-waarden, en het onderscheiden tussen statistische significantie en biologische relevantie. Het boek bevat ook talrijke voorbeelden uit verschillende biologische disciplines, die illustreren hoe de statistische principes in de praktijk toegepast kunnen worden.
Aanbevelingen:
- Lees het boek zorgvuldig: Neem de tijd om de concepten te begrijpen en oefen met de voorbeelden.
- Gebruik statistische software: Leer hoe je statistische analyses kunt uitvoeren met behulp van software zoals R, Python, of SPSS.
- Consulteer statistische experts: Als je vragen hebt of hulp nodig hebt, aarzel dan niet om een statisticus te raadplegen.
- Blijf op de hoogte: De statistische wetenschap evolueert voortdurend. Blijf op de hoogte van de nieuwste ontwikkelingen door vakliteratuur te lezen en conferenties bij te wonen.
Door deze aanbevelingen te volgen, kun je je vaardigheden in de analyse van biologische data verbeteren en bijdragen aan de vooruitgang van de biologische wetenschap. De correcte en robuuste analyse van data is essentieel voor het trekken van betrouwbare conclusies en het bevorderen van ons begrip van levende systemen.